Pro klienty hledám řešení pro technické nedostatky, které mají vliv na viditelnost webu ve vyhledávačích. Přesto jsem si ráda zašla na školení. Pro opravdu rozsáhlé weby doporučuji pány Pavla Ungra a Jardu Hlavinku.
Školení technické SEO nejen pro vývojáře od pánů od SEO fochu, Pavla Ungra a Jardy Hlavinky (ze Seznam.cz), je komplexní a informačně nabité. Doporučuji všem vývojářům i SEO konzultantům, kteří chtějí najít společnou řeč a řeší „nekonečné“ weby.
Pavel Ungr a Jarda Hlavinka představují harmonogram kurzu Technické SEO nejen pro vývojáře
Proč školení vzniklo? „Konzultanti nadávají na vývojáře. Vývojáři nadávají na konzultanty. Všichni mají v zásadě pravdu. Musíme se navzájem snažit pochopit,“ řekl Pavel.
Užijte si pár poznámek ze školení. A pokud školení chcete absolvovat, jsou zatím všechny termíny vyprodané. Ale raději se přesvědčte přímo u Pavla: Technické SEO nejen pro vývojáře. Případně se podívejte na jiné jeho školení.
Rozcvička na začátek
Pavel s Jardou na začátku rozebrali současný pohledu na SEO. A jaké problémy řešíme v roce 2018. Dost často už nemusíme chodit „ven“ z Googlu, odpověď už na nás čeká přímo tam. Narážíme na SERP Features – rozšířené výsledky vyhledávání. Nejen placené výsledky, ale také nákupy Google, Google mapy a rich snippety. SEO prý zabilo (not provided) v Google Analytics.
SEO rozhodně není mrtvé, jak se občas uvádí. Ani podvod na lidi.
V roce 2018 čím dál více můžeme i ČR mluvit o RankBrain. Strojovém učení, díky kterému se na základě chování uživatelů přepisují výsledky v SERPu.
Nejvíce důležitými faktory v roce 2018 jsou
Obsah
Odkazy
RankBrain
Technické SEO máme pod kontrolou
Říkají pánové na školení a já jim dávám za pravdu. Obsah z webu nám může někdo zkopírovat a vytvářet tak duplicity. Pohybovat se v linkbuildingu také neumí každý. Raketová věda to není, ale praxe musí nesmí chybět. A když si uvědomíme, že strojové učení RankBrain může změnit pořadí v SERPu dle toho, na jaké výsledky uživatelé klikají, nemůžete si být pořádně jisti ničím. Nebo právě jen tím, jak váš web funguje stran technického řešení. Pokud máte zkušeného a trpělivého vývojáře, který naslouchá a nepokládá SEO konzultanty za blbečky a kecálky. 🙂
Technické pasti na nepřipravené
Indexace
První část povídání byla zasvěcena indexaci.
Crawling vs. indexace
Rozdíl je v tom, že při crawlingu se roboti snaží stáhnout kód a při indexaci tzv. indexer ukládá do databáze a vrací v SERPu. Rozdíly mezi vyhledávačem Google a Seznam existují.
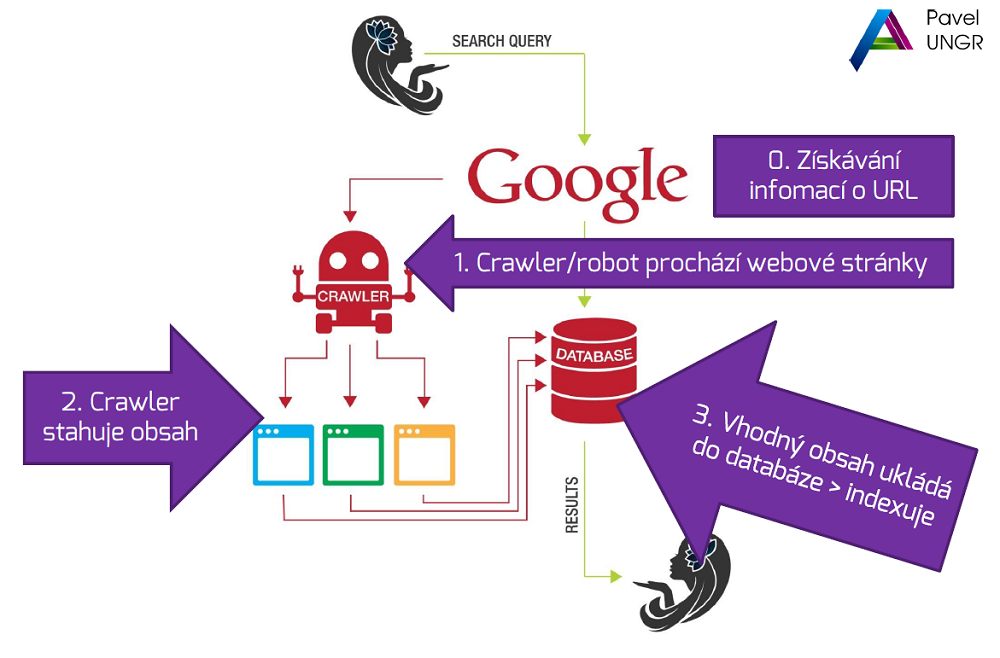
Procházení a indexace v Google
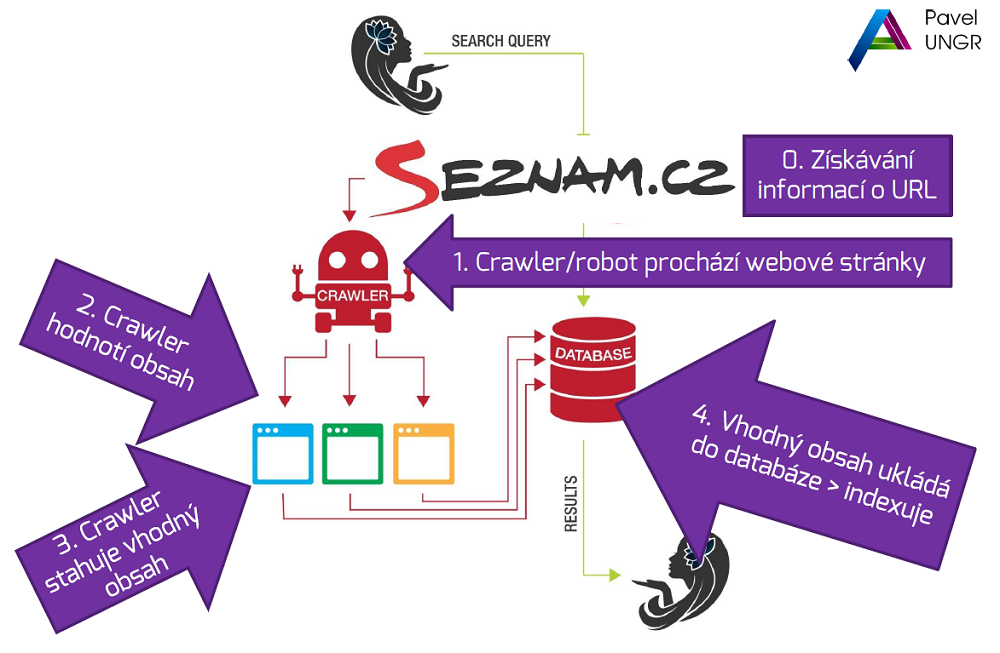
Procházení a indexace na Sezamu
Google zjistí URL, přijde na stránku a stáhne obsah. Vhodný ukládá do databáze. Na Seznam.cz přijde na stránku. Z důvodu výkonu se rozhoduje, zda bude stránku stahovat. Když se mu nelíbí (na stránce je lorem ipsum nebo je třeba prázdná), nemusí ji stahovat. Seznam.cz nemusí být pomalý, prostě jen nemá důvod stahovat.
Zákazy procházení a zákazy indexace
Pavel mluvil o zákazech procházení webu a zákazech indexace. Vždy nemusí být úplně jasné, co k čemu slouží. Já si ráda připomínám článek od Honzy Tichého: Robots.txt neslouží k zákazu indexace stránek.
Kodex dobré indexace
Líbil se mi termín Kodex dobré indexace. Myslím, že tímto kodexem jsou srozumitelně popsána pravidla Jak se dostat do vyhledávačů:
I. Poskytujte URL vyhledávačům
Odkazy – Vedou na vaše stránky odkazy z významných a indexovaných stránek?
Sitemap.xml – Máte odkazy v sitemap.xml? Je odkaz v robots.txt?
Omezení robota – třeba wordpress.com (1 x za 2 sekundy)
Příliš dlouhá odezva
Funkční web, který nezlobí
3 x a dost
Penalizace
Neblbněte s JavaScriptem – location.href
Co se indexuje a neindexuje
Na scénu nastoupil Jarda Hlavinka a začal rozebírat jednotlivé prvky, které jsou indexovány a naopak vyhledávači Google a Seznam.
Co se indexuje / neindexuje?
Tato část se samozřejmě neobešla bez diskuze, jak je to s indexací skrytého textu. Typicky záložky nebo ouška. V tuto chvíli platí, že na desktopu musí být text viditelný. Na mobilu to nevadí.
Další témata z technického školení
Sitemap.xml
Další velké téma byl soubor sitemap.xml. Jaké typy sitemap pro jaká média existují (URL adresy, videa, obrázky a zprávy). Jak může být soubor nejvíce velký a kolik maximálně URL adres. Jazykové mutace a parametry. Důležitá informace: URL v sitemap mohou být cross-domain. Do sitemap.xml patří jen důležité URL adresy (se stavovým kódem 200). Rozhodně tam nepatří URL vracející 40x, 50x ani 30x. Dejte pozor na URL, které jsou zakázané k indexaci, k procházení nebo jsou kanonizované.
Neindexace URL
Diskutovaly se důvody a řešení pro neindexaci URL adres. Začněte tím, že budete posílat do sitemap.xml pouze důležité URL adresy. Nechceme indexovat to, co je duplicitní, nedůležité a má nízkou prioritu. Může se jednat o různé řazení produktů v e-shopech, nedůležité filtrování, stránkování, atd. Kluci shrnuli možná řešení. Upozornili také na správnou strukturu URL adres. V některých nesprávně řešených e-shopech se můžete dostat ke stejné kategorii či produktů různými cestami, které se promítají do URL adresy. Díky tomu vznikají duplicitní vstupní stránky.
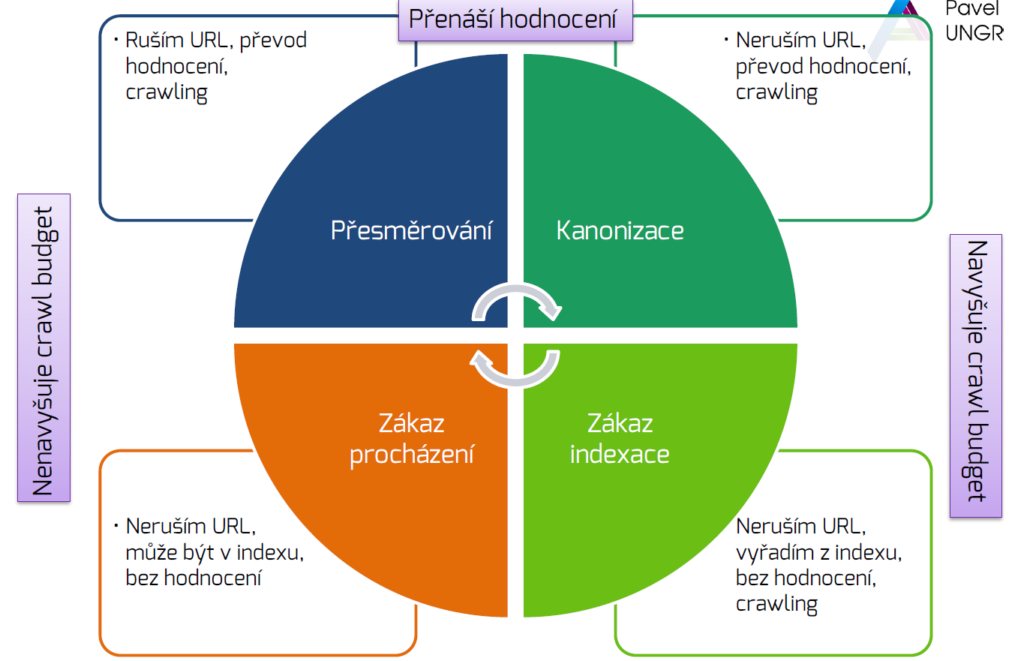
Přesměrování a kanonizace
Kdy použít jedno a kdy druhé? Při přesměrování již původní URL neexistuje, je to zásadní a rychlý krok. Hodnocení se přesunuje. Pokud URL „jen“ kanonizujete, původní URL stále existuje. Stále se na ní roboti dostanou a ubírají kapacitu z crawl budgetu. Hodnocení se také přesunuje. Když už přesměrováváte trvale, zvolte raději 301, než 302. A když přesměrováváte, počítejte s dočasným propadem. Vždy záleží na návštěvnosti webu a množství přesměrování. Po přesměrování nezapomeňte poslat aktuální sitemap.xml do Google Search Console.
Přesměrování nebo kanonizace. Co použít? Malá ochutnávka ze školení
Stránkování
Stránkování je možná na první pohled jasné. Ale pokud máte e-shop a chcete vymyslet pro stránkování nejlepší řešení, nejspíš zjistíte, že jednoduché řešení neexistuje. Aspoň pro nás v ČR, kde podíly drží 2 největší vyhledávače Google a Seznam. Pro Google existuje elegantnější řešení, které ale nepodporuje Seznam.cz. Cílem je, aby lidé ve vyhledávačích viděli jen první stránku kategorie e-shopu. Ty ostatní musí jen procházet, ale není žádoucí, aby je ukládal do indexu. Zároveň by měl předávat link juice. Na další stránky (kromě první) dejte noindex, follow.
Filtrace (fasetová navigace)
Jsme opět u e-shopu. Rozhodněte se, které filtry jsou důležité a které ne. K tomu vám pomůže klasifikační analýza klíčových frází. Pro důležité filtry musíte vymyslet indexovatelné a cralowatelné řešení. Nezapomeňte filtrované důležité stránky uvést v sitemap.xml. Tzn. každý filtr je odkaz a není vypsaný JavaScriptem. Filtrované stránky jsou obsahově unikátní (černé lednice Samsung/černé lednic Bosch). Pokud to technicky nevyřešíte dobře, nedostane se na fráze typu „zelená košile“, „modrá košile“. Omezíte přístup lidem z vyhledávačů. Kdo to má vyřešeno dobře? Mrkněte na:
Heureku
Glami
Bellarose
Co se na kurzu probíralo dál?
Spousta dalších přínosných věcí. Kdybych se snažila zmínit a popsat vše, zřejmě bych tuto recenzi a poděkování Jardovi a Pavlovi nikdy na blog neposlala. Tak jen krátce:
Automatizace textů
Jak na to, když musíte otextovat pár tisíc stránek na e-shopu. Texty můžete částečně automatizovat.
Vícejazyčné weby
Google dokáže rozpoznávat jazyk, ale někdy mu to nevyjde. Existuje hreflang 🙂
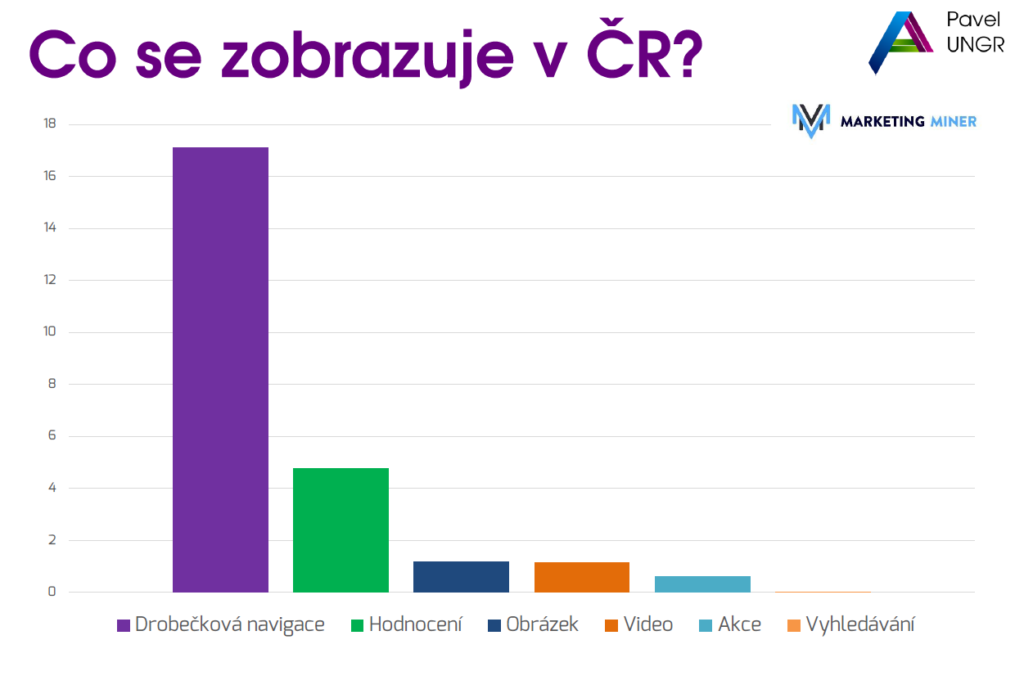
Strukturovaná data
Vyhledávačům popisují strukturu dat. Díky tomu můžeme vyjádřit, že zmíněná část textu je například nadpis článku, další zase obrázek či nějaká akce. Mimochodem, víte, co se zobrazuje v ČR? Zdroj: Marketing Miner a školení.
Optimalizace obrázků
Nezapomeňte na popisný název, atribut ALT, okolní text, strukturovaná data a sitemap.xml, pokud je to přínosné.
Penalizace, její druhy a řešení
Globální vs. lokální penalizace. Manuální vs. algoritmická. Jak je můžete vyřešit. A co všechno vyhledávačům vadí a zakazují? Zmiňme obtěžující popupy, neoriginální obsah, cloaking, skryté přesměrování, skrytý text, atd.
SEO a JavaScript
Část o webech napsaných skriptovacím jazyku JavaScript, kterou vedl Jarda Hlavinka. Upřímně říkám, že to bylo maso a že si umím představit pár hodinové školení věnované jen této problematice. Pokud vás trápí něco kolem JS webů, určitě se ozvěte Jardovi. AJAX Crawling, _escaped_fragment_=, Server-side rendering. K pochopení budu bych si představovala více času nejen na školení, ale hlavně doma a v praxi. Tvrdím, že je to moje mezírka. A Jarda je borec! 🙂
Access logy
Proč je vhled do Access logů důležitý, co v nich hledat a jaké nástroje pomohou. Když se rozhodnete zkoumat Access logy z webu, hledejte chyby 400 a 500. Přesměrování, odchylky a jejich vzory. Máte šanci, že zjistíte více, než ze XENU, Sreaming Frog a analytických nástrojů. V případě ztracení v příkazové řádce bych se poradila s pány Pavlem a Jardou nebo bych se zeptala u Filipa ;). Na SEOlogeru 2017 vystoupil s přednáškou: Server logy a jak je využít pro SEO.
Page speed
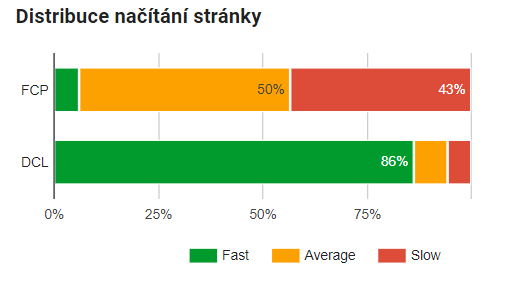
Souhlasím s větou z prezentace: „Kvůli SEO vyřešte základ, kvůli lidem zrychlujte co to jde.“ Při prvních průzkumech rychlosti stránky si pomáhám nástroji Marketing Miner nebo PageSpeed Tools. V PageSpeed došlo v tomto roce ke změně a nově se měří rychlost vykreslování stránek, ve skutečném prohlížeči Google Chrome. Nově tu uvidíte Distribuci načítání stránky aneb kolik procent prvků na stránce spadá do rychlostí Fast, Average a Slow.
Distribuce načítání stránky v PageSpeed Insights
Někdy může být na vině pomalý hosting. Prověřte webhosting nebo server po stránce výkonu. Několik testování hostingů najdete v článku Jak otestovat rychlost a výkon hostingu.
Dobrý webhosting = základ pre rýchly web. WebSupport je podľa mňa najlepší slovenský hosting v pomere cena/kvalita.
Roland Vojkovský
Přechod z http na https, redesign a nová doména
Když přecházíte, projděte si nejdřív článek Co si pohlídat při přechodu na HTTPS? Považuji ho za jeden z nejvíce srozumitelných článků v ČR. Když se chystáte k těmto krokům, nezapomeňte mít u sebe schopného SEO konzultanta. Je škoda přijít o zajímavou viditelnost a dobré hodnocení ve vyhledávačích díky přešlapům.
Za školení díky
Školení je super, zkuste se na něj dostat. Nebo se obraťte na Pavla či Jardu, pokud máte nějaké otázky či pochybnosti. Kluci často odpovídají ve FB skupině: SEOloger: Veřejná diskuse o SEO.
V životě se často snažíme najít tu nejlepší cestu. Někdy jde o zásadní rozhodnutí, třeba jestli se ostříhat na mikádo, nebo si nechat prodloužit vlasy.…
Umělá inteligence (AI) vstupuje na scénu copywritingu s velkým potenciálem změnit způsob, jakým tvoříme obsah. Zatímco někteří se obávají, že AI může lidem „ukrást” práci,…
Když je dobrý developer, tak technické SEO určitě není překážkou, ale může být docela dobrou konkurenční výhodou 🙂
Spravovat souhlas s cookies
Abychom vám mohli poskytovat co nejlepší služby, používáme k ukládání a/nebo přístupu k informacím o vašem zařízení technologie, jako jsou soubory cookie. Souhlas s těmito technologiemi nám umožňuje zpracovávat údaje, jako je chování při prohlížení nebo jedinečné ID na těchto stránkách. Neudělení souhlasu nebo jeho odvolání může negativně ovlivnit některé funkce a vlastnosti.
Funkční
Vždy aktivní
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Předvolby
Technické uložení nebo přístup je nezbytný pro legitimní účel ukládání preferencí, které nejsou požadovány odběratelem nebo uživatelem.
Statistiky
The technical storage or access that is used exclusively for statistical purposes.Technické uložení nebo přístup, který se používá výhradně pro anonymní statistické účely. Bez předvolání, dobrovolného plnění ze strany vašeho Poskytovatele internetových služeb nebo dalších záznamů od třetí strany nelze informace, uložené nebo získané pouze pro tento účel, obvykle použít k vaší identifikaci.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.













Když je dobrý developer, tak technické SEO určitě není překážkou, ale může být docela dobrou konkurenční výhodou 🙂