Filip Podstavec spustil nástroj Marketing Miner. Pokud se chcete s nástrojem blíže seznámit, zkoušejte ho a sledujte Filipovy videonávody na YouTube nebo projděte stručnou a jasnou Akademii Marketing Mineru.
Nebo náš blog. Dnes se s námi můžete vydat do části zvané URL Miner. V článku se dozvíte, co všechno se pod tímto názvem skrývá a k čemu vám URL Miner může pomoci. Na konci se zaměříme na miner Fulltext Index Checker, který pomáhá zjistit, zda jsou vložené URL stránky indexované či nikoliv.
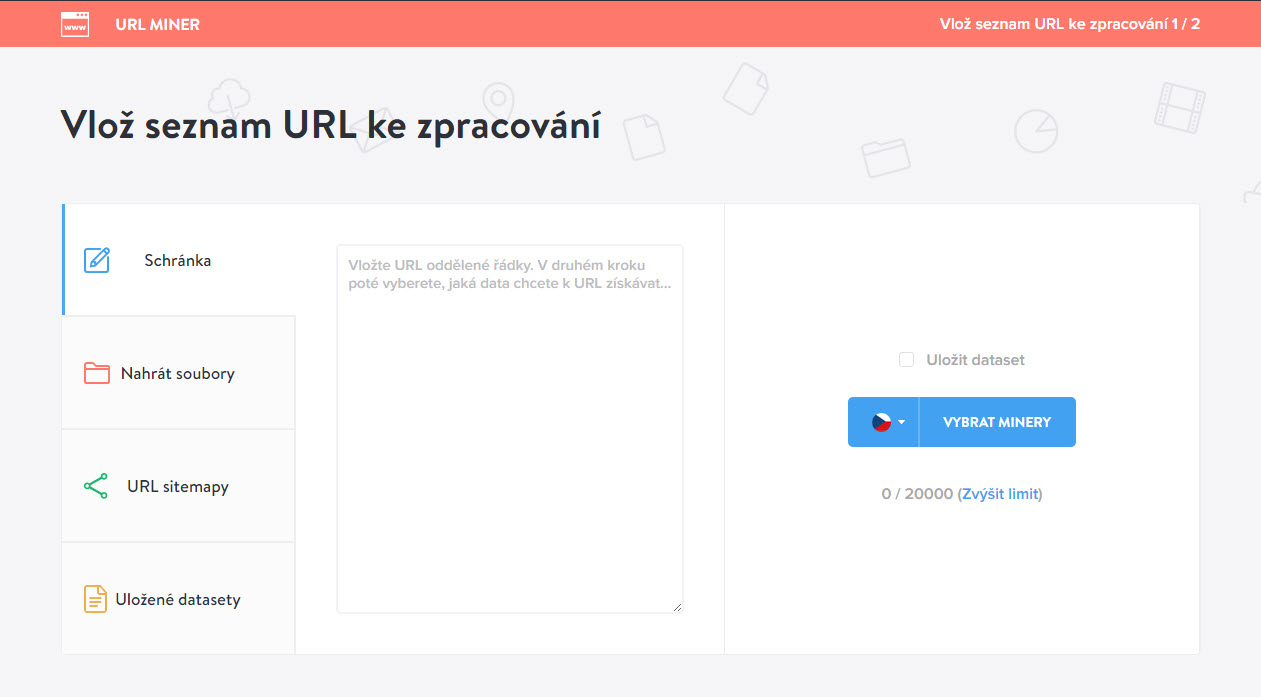
Do URL Mineru vložíte seznam URL adres ke zpracování několika způsoby.
K čemu slouží URL Miner?
URL Miner je nástroj, ze kterého dostanete informace o technickém stavu URL stránek nebo zda jsou indexované roboty. Jednoduše si uděláte obsahovou analýzu webu bez jediného pohledu na konkrétní URL adresy. Získáte informace o příchozích odkazech nebo jaké stránky jsou nejvíce sdílené na sociálních sítích.
Vložte adresy do URL Mineru
Do URL Mineru můžete vložit seznam URL adres 3 způsoby:
- Můžete je zkopírovat ze schránky;
- Můžete nahrát soubory z disku (* CSV, TXT, XLSX, ODS (UTF-8, UTF-16);
- Můžete vložit URL sitemapy webu. Pozor, pokud máte více sitemap na webu či sitemap, která odkazuje na další sitemapy, tak jediný způsob, jak tam dostat všechny, je nahrávat je po jedné.
Pokud plánujete s vloženými URL pracovat častěji, využijete poslední záložku: Uložené datasety.
Vložte URL různými způsoby
Vložte URL a vyberte minery

Ukázka vložených jednotlivých URL adres
Vyberte si, jakým způsobem dostanete URL adresy do systému (1), jazykovou mutaci (2), zvolte Uložit dataset (3) a klikněte na VYBRAT MINERY (4).
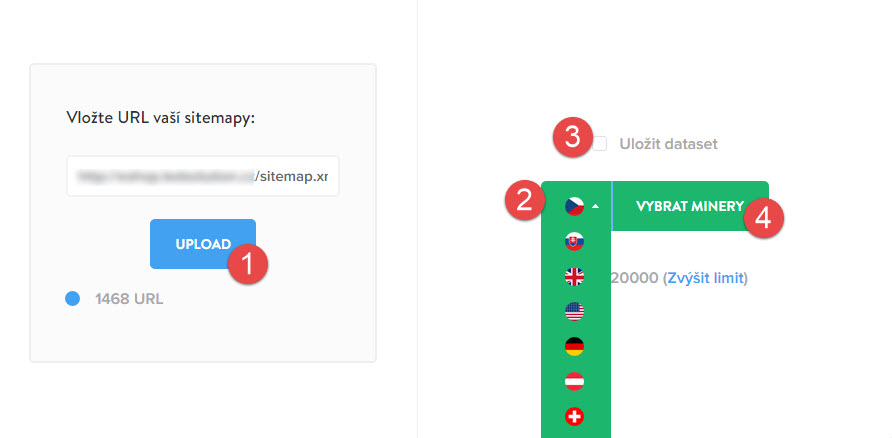
Vložte URL adresy do systému (1), vyberete si jazykovou mutaci (2), zvolíte Uložit dataset (3) a kliknete na VYBRAT MINERY (4).
Co můžete k URL adresám zjistit?
Na dalším kroku si můžete zvolit minery, které vás zajímají:
- Návrh a získávání nových frází pomocí AdWords Suggest
- Analýza URL stránek
- Zjistěte si Status Code URL adresy,
- rychlost stránek pomocí Page Speed,
- Security Analysis vám prozradí, zda jsou stránky z pohledu Google bezpečné,
- můžete si ofotit jednotlivé stránky pomocí mineru Screenshot,
- nebo propojit se službou Ahrefs.
- Kontrola indexace
- Pomocí Fultext Index Checker, na který se podíváme podrobněji.
- Pro linkbuildery nástroj nabízí
- Miner Social Signals, ze kterého zjistíte, který obsah se nejvíce sdílí a proč,
- Backlink Identification zkontroluje, zda odkaz existuje, na jakém místě a co je v okolí.
- Informace o obsahu
- Proveďte jednoduše obsahovou analýzu pomocí Content Analysis (title, meta description, Word count, Paragraph count,…)
- Plagiarism Checker odhalí URL s duplicitním obsahem,
- pomocí Broken Link Checkeru zkontrolujete vložené URL adresy a zda z nich nevede odkaz na neexistující URL adresu.
Testování indexace URL stránek
Pokud chcete zjistit, zda máte URL adresu ve výsledcích vyhledávání, není nic jednoduššího, než použít miner Fulltext Index Checker. Můžete také zaškrtnout volbu Kontrola výstup. URL. Tato možnost vám zkontroluje, jak přesně vypadá URL adresa ve výsledcích vyhledávání a zda se shoduje s tou, kterou jste do nástroje vložili.
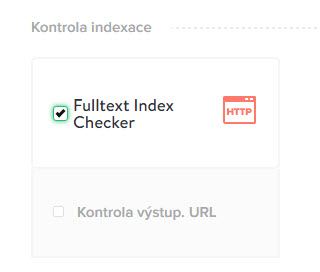
Díky Fulltext Index Checker, který pracuje s operátorem operátorem info:, zjistíte, jaké URL adresy mají vyhledávače zaindexované. Podle toho můžete hledat vzory těch, které v indexu nejsou, analyzovat a promyslet, jak to napravit.
Moment, report se zpracovává
V tuto chvíli máte čas na kávu či dobrý Rooibos čaj! 🙂
Výstup
Výstup pak vypadá takto: url-miner-2016-06-08_14-06-06-info. Můžete s ním dále pracovat v Excelu nebo v nástroji OpenRefine.
Jak pracují vyhledávače
Ve třech krocích:
- Roboti vyhledávačů sbírají data
- Pak přichází proces indexace
- Návštěvníci pak při kladení dotazů ve vyhledávačích dostávají seřazené výsledky
Proč URL adresy nejsou v indexu vyhledávačů
Je možné, že je web nový a roboti vyhledávačů ho nestihli ještě celý projít. Nebo jste právě přidali novou stránku. Vyhledávačům chvíli trvá, než ji projdou a zaindexují. Zvláště pokud nemáte soubor Sitemap nebo na novou stránku vyhledávače neupozorníte.
Také pokud na stránku nevede žádný interní či externí zpětný odkaz (tzv. linkbuilding), může to být důvod, proč se do výsledků vyhledávání nedostane.
Dále mohou být neindexované stránky blokované metaznačkami. Podívejte se na pár stránek do kódu, zda v hlavičce neuvidíte: <meta name="robots" content="noindex">. Zkontrolujte soubor robots.txt, jestli náhodou neblokujete přístup k těmto stránkám nebo do nějaké adresáře.
Prostudujte: https://support.google.com/webmasters/answer/34444?hl=cs
Indexace SeznamBotem
Přečtete si informace v nápovědě Seznamu: Fulltextové vyhledávání -indexování.
Dušan Janovský ze Seznamu v rozhovoru o fulltextovém vyhledávání na Seznam.cz řekl: „Copak o to, my bychom chtěli indexovat leccos. Ale s konečným počtem serverů jednou musí jednou přijít n-tá miliarda stránek, kterou už do indexu nenarveme. A tehdy se musíme rozhodnout, co do indexu dát a co ne. Spíše než bariéry jsou to nějaké fuzzy veličiny, s nimiž se zvyšuje nebo snižuje pravděpodobnost zařazení do indexu. Pak existují situace, kdy indexovat chceme, ale nedokážeme. Typicky velké servery, které na to, kolik mají obsahu, nestíhají odpovídat. Případně nás také blokují.“
Celý rozhovor si můžete přečíst na webu konzultanta Lukáše Pítry.
Indexace Googlebotem
Přečtěte si informace v nápovědě Search Console: Googlebot.
Jaká jsou obvyklá řešení
- Vytvářejte a aktualizujte sitemapy – Nezapomínejte na soubor Sitemap. Nahrávejte ho také do nástroje Google Search Console.
- Používejte nástroje pro přidání jednotlivých stránek – Submit URL to Google a Přidání stránky do vyhledávání Seznam.cz
- Nevytvářejte podobné stránky – snažte se nevytvářet podobné stránky. Někdy je to obtíž, hlavně u produktů, které se podobně jmenují, běžně se označují jenom čísly, mají podobné parametry atd. Problém taky může být špatný CMS systém, který vás nutí pro každou barvu či trochu jiný rozměr vytvořit úplně novou stránku.
- Kanonizujte preferovanou URL – Pokud jsou si stránky velmi podobné, nezapomeňte kanonizovat stránku, kterou do vyhledávání dostat potřebujete.
Další informace
- Kontrola výkonu stránek ve vyhledávání – nápověda pro Search Console od Google.
- Indexace ve vyhledávačích – článek z konce roku 2013 od Lukáše Pítry, stále informačně velmi hodnotný.
- Kontrola indexace stránek z akademie nástroje Marketing Miner.




Super článek a parádní nástroj. Jen chci doplnit, že je tam dnes (10.6.2016) limit 2000 dotazů přímo na fuknci kontroly indexace. To tam před měsícem ještě nebylo. A zrovna by se mi to hodilo 😀